
Empirical benchmarking for synthetic minds.
Sapient Eval is an open-source, AGPL-3.0+ compliant benchmarking framework designed to bring structured, reproducible measurement to synthetic intelligence systems. It provides a standardized way to evaluate AI models across key dimensions such as accuracy, reasoning ability, latency, and computational efficiency. Rather than relying on opaque or inconsistent evaluation methods, Sapient Eval focuses on transparency, modularity, and reproducibility so that every result can be inspected, repeated, and compared under identical conditions.
At the core of Sapient Eval is a modular benchmark engine that allows users to define and execute evaluation workflows through a flexible, plugin-based architecture. Models can be connected through universal adapters, enabling support for locally hosted systems, API-based models, or distributed inference setups. This makes it possible to benchmark everything from lightweight local models to large-scale systems using the same standardized evaluation pipeline.
A defining feature of Sapient Eval is its Industry Specification System (BMS), which allows users to define structured benchmark environments tailored to specific domains such as legal, finance, healthcare, or engineering. Each specification can define task types, constraints, scoring weights, and evaluation rules, enabling highly customized yet consistent benchmarking across different industries and use cases.
Sapient Eval also includes a multi-dimensional scoring system that goes beyond simple accuracy metrics. It evaluates models based on response quality, reasoning depth, latency, token efficiency, and system resource usage, producing a balanced view of performance. Combined with reproducible execution, versioned datasets, and model comparison tools, Sapient Eval enables developers and researchers to track improvements, detect regressions, and objectively compare competing models over time.
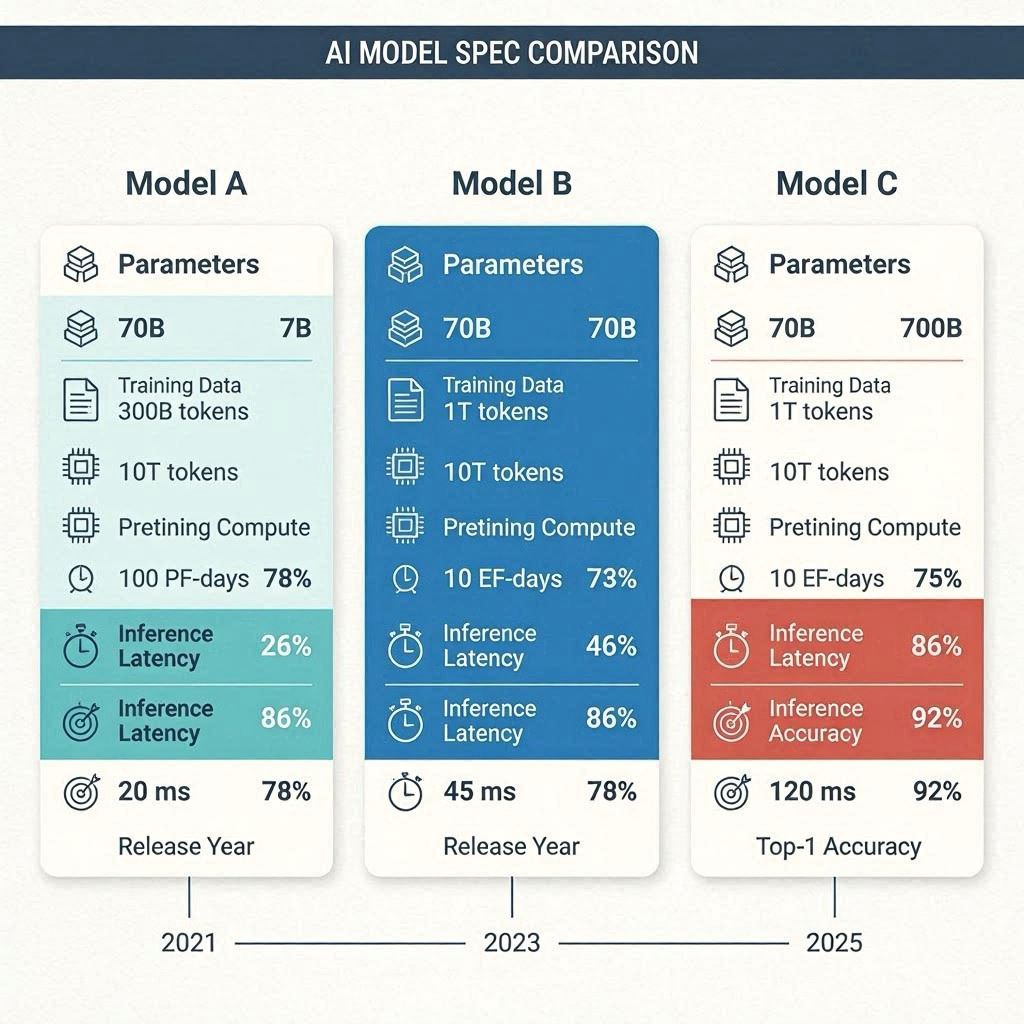
- Sapient Eval – An open-source, AGPL-3.0+ compliant benchmarking framework for empirically evaluating synthetic intelligence systems across accuracy, speed, efficiency, and reasoning performance.